* Colab에서 작성되었습니다.
전편 (https://mkk4726.tistory.com/20) 에서 만든, 홈페이지 정보를 가지고 있는 meta.csv를 이용해 이번에는 원하는 정보들을 추출해올 것이다.
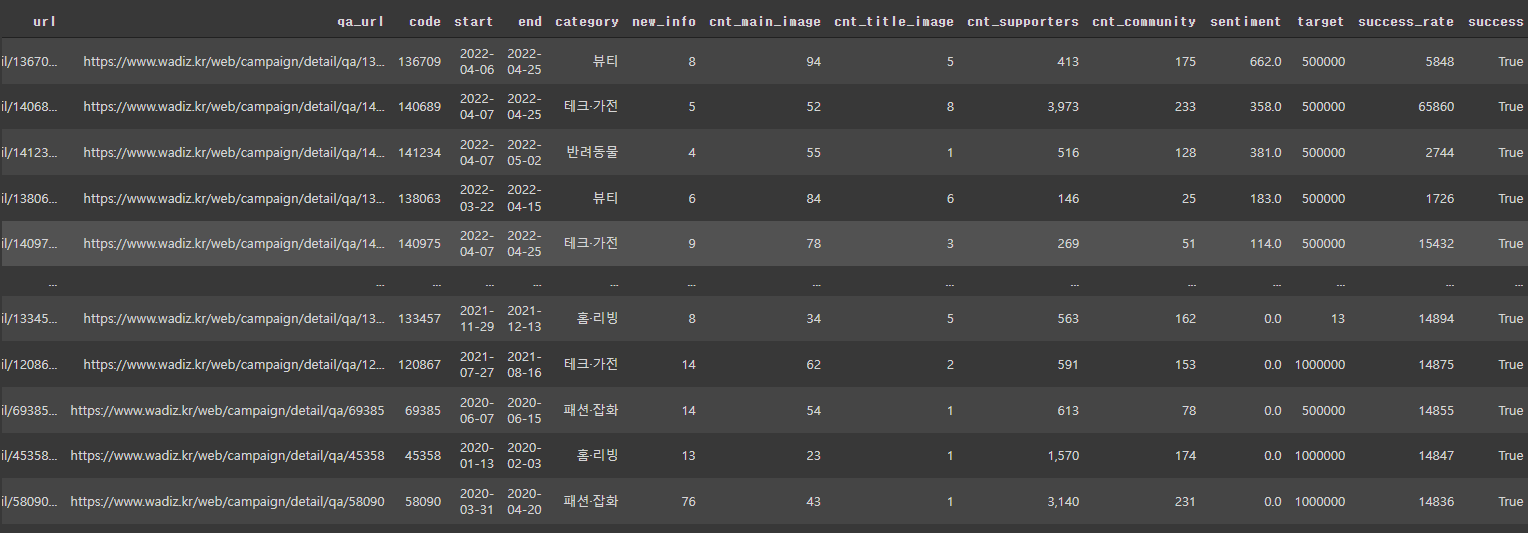
기간, 새소식 수, 본문에 있는 이미지 수, 제목에 있는 이미지 수, 커뮤니티 댓글 수, 커뮤니티 댓글 감성분석 결과, 목표 금액 등을 예측변수로, 성공여부를 종속변수로 가지는 데이터를 만들었다.
아직 실력이 부족해 모르는 것들을 배우고, 시행착오를 겪느라 하루를 이 작업에 투자했다.
해당 코드는 첨부한 Code(1).ipynb를 통해 확인할 수 있다. 이 과정을 하나씩 설명해보겠다.

먼저 Selenium과 Konlpy를 설치해준다.
Konlpy를 Jupyter notebook에서 사용하기 위해 설치할 때는 꽤나 고생했던 것 같은데 찾아보니 저렇게 한 줄로 설치할 수 있어서 놀랐다. 그 덕에 편리하게 사용할 수 있었다.

그 후 라이브러리들을 임포트해주고 selenium을 설치해준다. 그리고 구글 드라이브를 연동해서 저번에 만든 meta.csv 파일을 불러왔다. 이렇게 셋팅을 마쳤다.
데이터를 수집하는 과정은 크게 2가지로 구성된다.
감성분석과 나머지 데이터 수집
1. 데이터 수집

데이터 수집은 다음과 같이 진행되었다. 여기서 get_data는 내가 만든 함수로 이어서 설명하겠다.
나는 코드를 짤 때 함수로 정리하는 것을 좋아한다.
이는 권철민 교수님의 강의를 들은 영향이 큰 것 같은데,
어쨌든 함수로 정리하면 결과를 내는 코드가 깔끔해져 진행할 때 편리하기 때문이다.
try, except 구분을 이용해 데이터 수집이 완료되거나 도중에 오류가 나더라도 데이터가 날라가지 않게 바로 저장하도록 설정해주었다.


이렇게 get_data함수를 짰다. 짤 때 약간의 노가다가 들어가서 시간은 오래걸렸으나 특별한 로직이 있는 함수는 아니다.
수집할 정보들을 하나의 리스트로 담아 반환하는 함수다.
이 함수를 그림 4처럼 url에 하나씩 적용해 전체 데이터를 수집해주었다.
그리고 이를 나중에 정리해주었다. 이렇게 간단하게(?) 1번 작업이 끝났다.
2. 감성분석
그 다음으로는 커뮤니티의 댓글들에 대해서 감성분석을 진행했다.

이 또한 위에서와 마찬가지로 함수를 만들어 사용했다.
내가 짜서 그렇게 느끼는 건지 모르겠지만, 함수를 사용하니 결과내는 출력창이 깔끔해 보기가 참 좋은 것 같다.
감성분석의 과정은 커뮤니티 댓글 수집 -> 단어와 빈도수로 구성된 dataframe 생성 -> 감성분석 사전을 이용해 score 계산으로 이루어있다.

한국어 감성사전은 KNU 한국어 감성사전(http://dilab.kunsan.ac.kr/knusl.html)을 이용했다.
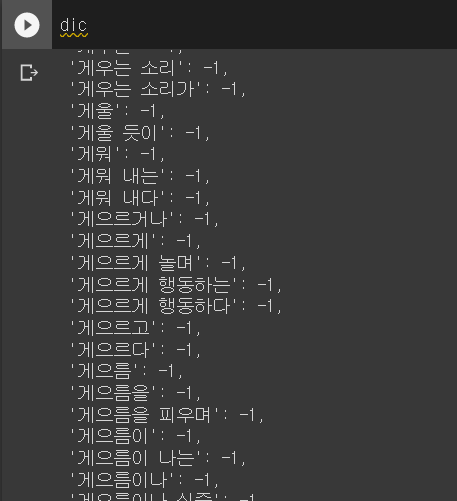
txt파일을 불러와 다음과 같이 dictionary형태로 만들어 사용하기 쉽게 만들었다. 그림 9에서 볼 수 있 듯,
긍정단어는 +를 부정단어에는 -를 부여해 이러한 단어의 총합으로 문장의 감성을 판단하는 것이다.
또한 쓸모없는 말을 의미하는 불용어 사전을 불러와 전처리시에 활용했다. (그림 8)
또한 konlpy의 okt를 이용해 문장을 형태소 단위로 나누었다.

홈페이지의 특성상 더보기를 눌러야 댓글이 더 보이는 상황이라 더보기를 눌러줬다. 더 이상 누를게 없으면 오류가 나기에 오류가 나기 전까지 더보기를 눌러줬다.
그 후 cnt를 계산해줬는데, 이는 커뮤니티에 작성된 댓글 수를 따온 것이다. 0일 경우 오류가 나서 예외 처리를 해준 모습이다. cnt가 0일 경우 감성분석이 의미가 없기에 점수와 개수를 모두 0으로 반환하고 끝내도록 만들었다.

그 후 댓글을 구했다.
정규식을 이용해 가~힣이 아닌 단어는 없애주었다.

그 후 new_df(그림 13)를 만들어주기 위해 sklearn의 CountVectorizer를 이용했다. ngram을 사용할게 아니라면 otk로 형태소 분석만 해주면 되지만 ngram을 사용하기 위해 이러한 과정을 거쳤다.
ngram이란 단어의 연걸(?)정도로 이해하면 될 것 같다. 단어의 빈도로만으로는 문맥을 이해할 수 없기에 이를 보완하기 위해 사용되는 기법으로, '나는 밥을 먹었다'를 형태소 분석하면 나, 는, 밥, 을, 먹었, 다 로 나뉘어진다.
ngram = 2로 분석하게 되면 나는, 는밥, 밥을, 밥먹었, 먹었다 와 같이 나뉘어지게 된다.

그 후 이 단어들을 앞서 언급한 감성사전에서 찾아, total점수를 계산해내는 것이다.
이렇게 2번과정도 끝이 났다.
그렇게 구해진 데이터들을 합치고 몇가지 전처리를 거쳐 최종 데이터를 완성하게 되었다.

하기 전에는 참 막막했는데, 하고 나니 진짜 별거없다는 생각이 든다.
이해했다는 근거 중 하나를 만족하는 순간이다. 설명도 마쳤으니 이해했다고 봐도 무방하겠다.
확실히 코딩은 하면 할 수록 느나보다. 이것저것 짜다보니 과거의 내가 우러러 볼만한 코드들을 짜고 있다.
아직 한참 부족하지만 그래도 위안을 얻을 수 있는 포인트이지 않나 싶다.
아마 누가 내 블로그를 보겠느냐마는, 읽으신 분들 중에 코딩이 어렵게 느껴지신다면 짠 코드를 함수로 정리해보는 습관을 들여보라 추천하고 싶다. 훨씬 깔끔한 코드르 짤 수 있게 될 것이다.
'DataScience > Crawling & Scraping' 카테고리의 다른 글
| 더보기, LoadMore 눌러야 할 때 ( dynamic crawling ) (0) | 2023.07.04 |
|---|---|
| Scraping IMDb review data (0) | 2023.07.02 |
| 네이버 금융 web scraping (0) | 2022.04.19 |
| 데이터 뽑아내기_ YouTube (0) | 2022.04.12 |
| 와디즈 url, 상품 코드 가져오기 (0) | 2022.04.08 |




댓글