Scraping IMDb review data
https://github.com/mkk4726/CB-movie
GitHub - mkk4726/CB-movie: Content-based filtering about movie
Content-based filtering about movie . Contribute to mkk4726/CB-movie development by creating an account on GitHub.
github.com
이번 글의 코드를 crawling-scraping 폴더에서 찾을 수 있습니다.
IMDb data를 이용해 영화를 추천하는 프로젝트를 진행하고 있습니다.
리뷰가 비슷한 영화를 추천해주면 만족하겠다라는 가정을 세우고,
리뷰를 기반으로 유사도를 측정해 추천하려 합니다.
이를 위해 데이터를 긁어와야합니다.

위 페이지의 url을 보면,
https://www.imdb.com/title/tt13024974/reviews?sort=totalVotes&dir=desc&ratingFilter=0
해당 부분이 title id이고 이것만 바꿔주면 쉽게 리뷰를 긁어올 수 있음을 알 수 있습니다.
따라서 해야할 일은 2가지입니다.
1. 영화별 title id 구하기
2. 해당 페이지에서 리뷰 긁어오기
1. 영화별 title id 구하기
1번 내용과 관련한 코드는 read-data.ipynb에서 확인해볼 수 있습니다.
영화별 title id는 IMDb에서 제공하는 dataset을 통해 구할 수 있습니다.
https://developer.imdb.com/non-commercial-datasets/
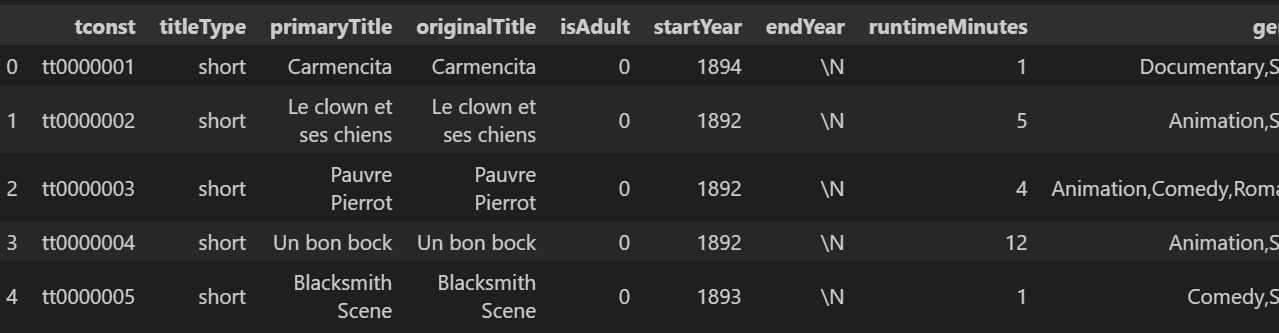

여러가지 파일 중 title.basics.tsv.gz과 title.ratings.tsv.gz 파일을 inner join해서 사용했습니다.
영화가 굉장히 많은데 3가지 조건을 부여해 16000개정도의 후보를 추려냈습니다.
cond1 = title_basic_ratings_df['averageRating'] > 7.900000e+00 # 평균평점이 7점 이상 , 상위 75% 기준
cond2 = title_basic_ratings_df['numVotes'] > 1.010000e+02 # 투표 수가 1000개 이상 , 상위 75% 기준
cond3 = title_basic_ratings_df['startYear'] > 2.017000e+03 # 시작일이 2002년 이상 , 상위 50% 기준
candidate_list = title_basic_ratings_df[cond1 & cond2 & cond3]['tconst'].tolist()2. 해당 페이지에서 리뷰 긁어오기
2번내용은 긁어오는 함수 구현하기와 멀티 프로세싱을 이용해 실행하기로 나누어집니다.
2-1. Scraping function
2-1번 내용과 관련한 코드는 scraping_review.ipynb에서 확인해볼 수 있습니다.
데이터를 긁어오는 과정은 생각보다 굉장히 단순합니다.
먼저 해당 페이지에서 html 파일을 get하고 BeautfulSoup을 이용해 parsing해줍니다.
import requests as re
from bs4 import BeautifulSoup as bs
title_id = 'tt0302617'
url = f'https://www.imdb.com/title/{title_id}/reviews?sort=totalVotes&dir=desc&ratingFilter=0'
res = re.get(url)
if res.status_code == 200:
html = res.text
soup = bs(html, 'html.parser')
print(soup)
else:
print(res.status_code)
그 후에는 selector를 찾아옵니다.
순서는 다음과 같습니다.
1. ctrl + shift + I 눌러서 개발자 모드 들어가기
2. 좌측 상단의 화살표 표시 누르기
3. 원하는 부분 클릭하기
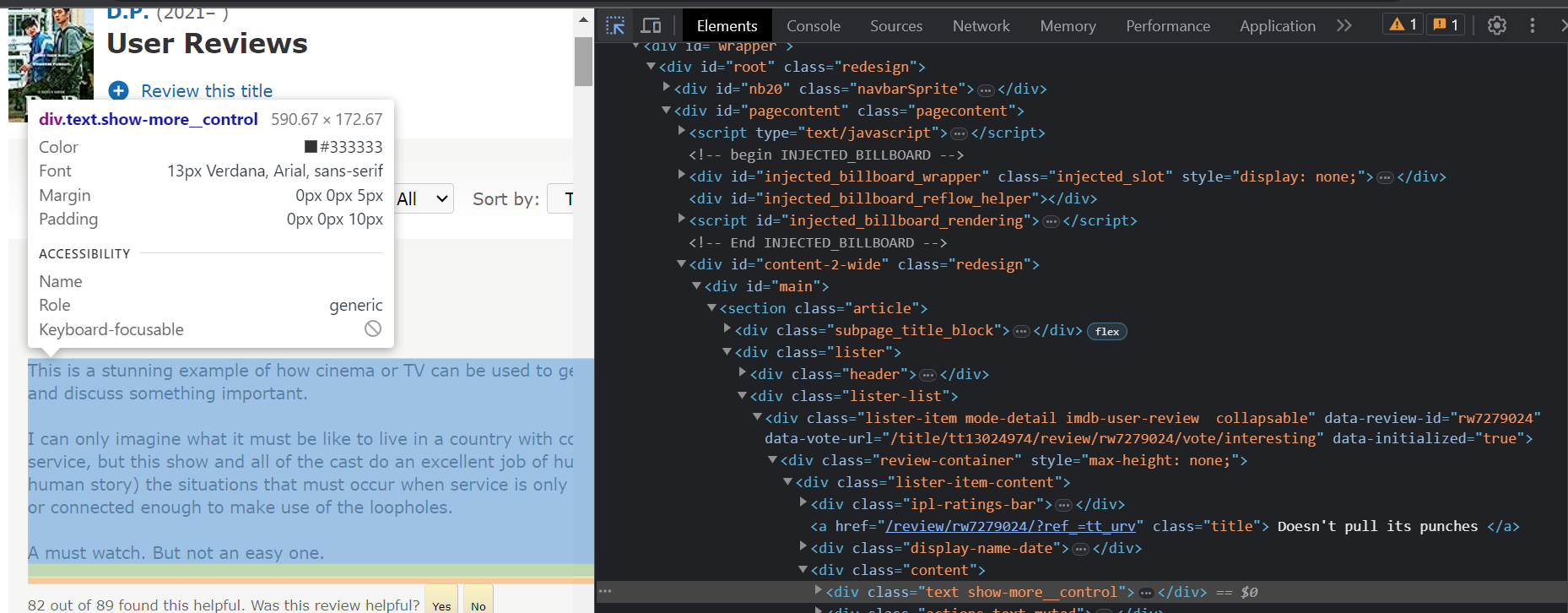
4. 마우스 우측눌러서 해당 selector 복사하기

이를 이용하면 원하는 값을 쉽게 찾아올 수 있습니다.
text_list = []
rating_list = []
title_list = []
user_list = []
date_list = []
try:
i = 1
while True:
main_selector = f'#main > section > div.lister > div.lister-list > div:nth-child({i}) > div.review-container > div.lister-item-content'
text_selector = f'{main_selector} > div.content > div.text.show-more__control'
text_list.append(soup.select(text_selector)[0].text)
rating_selector = f'{main_selector} > div.ipl-ratings-bar > span > span:nth-child(2)'
rating_list.append(soup.select(rating_selector)[0].text)
title_selector = f'{main_selector} > a'
title_list.append(soup.select(title_selector)[0].text)
user_selector = f'{main_selector} > div.display-name-date > span.display-name-link > a'
user_list.append(soup.select(user_selector)[0].text)
date_selector = f'{main_selector} > div.display-name-date > span.review-date'
date_list.append(soup.select(date_selector)[0].text)
print(f"{i} is done")
i += 1
except:
print('end')여기서 한가지 추가로 알아야하는 것은, 리뷰 데이터는 여러개가 있고 이는 div:nth-child를 이용해 관리됩니다.
따라서 이 부분의 값을 바꿔주면, 전체 리뷰 데이터를 찾아올 수 있습니다.
최종적으로 만들어진 함수는 다음과 같습니다.
import requests as re
from bs4 import BeautifulSoup as bs
import pandas as pd
def get_review(title_id: str, verbose: bool=True) -> "pd.DataFrame":
"""IMDb에서 review data를 sraping해오는 func
Args:
title_id (str): 영화별 고유 id
verbose (bool, optional): scraping 과정을 출력할건지 여부
Returns:
pd.DataFrame: [rating, title, review, user, date] column을 가진 dataframe
"""
url = f'https://www.imdb.com/title/{title_id}/reviews?sort=totalVotes&dir=desc&ratingFilter=0'
res = re.get(url)
if res.status_code == 200:
html = res.text
soup = bs(html, 'html.parser')
else:
print(res.status_code)
return
text_list = []
rating_list = []
title_list = []
user_list = []
date_list = []
try:
i = 1
while True:
main_selector = f'#main > section > div.lister > div.lister-list > div:nth-child({i}) > div.review-container > div.lister-item-content'
text_selector = f'{main_selector} > div.content > div.text.show-more__control'
text_list.append(soup.select(text_selector)[0].text)
rating_selector = f'{main_selector} > div.ipl-ratings-bar > span > span:nth-child(2)'
rating_list.append(soup.select(rating_selector)[0].text)
title_selector = f'{main_selector} > a'
title_list.append(soup.select(title_selector)[0].text)
user_selector = f'{main_selector} > div.display-name-date > span.display-name-link > a'
user_list.append(soup.select(user_selector)[0].text)
date_selector = f'{main_selector} > div.display-name-date > span.review-date'
date_list.append(soup.select(date_selector)[0].text)
if verbose:
print(f"{i} is done")
i += 1
review_df = pd.DataFrame()
review_df['review'] = text_list
review_df['rating'] = rating_list
review_df['title'] = title_list
review_df['user'] = user_list
review_df['date'] = date_list
except:
print(f'{title_id} end')
return review_df
2-2. 멀티 프로세싱을 이용해 수집하기
2-2번 내용과 관련한 코드는 scraping.py와 modules.py에서 확인해볼 수 있습니다.
앞서 3가지 조건을 이용해 구한 후보군을, 위에서 구현한 함수(get_review)로 하나씩 불러오는 것입니다.
어떤 title id에 대한 것인지 확인하기 위해 get_review함수의 return값에 title_id를 추가했습니다.
16000개정도이고, 한 개당 대략 2초정도 걸리니 8~9시간정도가 소요될 것으로 예상됩니다.
이를 multiprocessing을 이용해 단축시킬 수 있습니다.
제 컴퓨터는 CPU가 8개라, 간단히 생각하면 8분의 1로 시간을 단축시켰고, 이런저런 소요시간을 더해주면 그보다는 더 걸릴 것으로 예상됩니다.
실제 소요시간은 45분정도가 걸렸습니다.
이 과정을 tqdm을 이용해 확인했습니다.
완료 후 결과는 pickle 파일로 저장했습니다.
import pandas as pd
from modules import get_review, save_result_to_pickle
import multiprocessing as mp
import tqdm
if __name__ == '__main__':
title_basic_ratings_df = pd.read_csv('C:/Users/Hi/Desktop/CB(movie)/data/title_basic_ratings_df.csv', index_col=0)
cond1 = title_basic_ratings_df['averageRating'] > 7.900000e+00 # 평균평점이 7점 이상 , 상위 75% 기준
cond2 = title_basic_ratings_df['numVotes'] > 1.010000e+02 # 투표 수가 1000개 이상 , 상위 75% 기준
cond3 = title_basic_ratings_df['startYear'] > 2.017000e+03 # 시작일이 2002년 이상 , 상위 50% 기준
candidate_list = title_basic_ratings_df[cond1 & cond2 & cond3]['tconst'].tolist()
n_CPU = mp.cpu_count()
pool = mp.Pool(processes=n_CPU)
results = []
for result in tqdm.tqdm(pool.imap_unordered(
get_review, candidate_list), total=len(candidate_list)):
results.append(result)
save_result_to_pickle('C:/Users/Hi/Desktop/CB(movie)/data\scraping_results/results_2.pickle', results)
# with mp.Pool(n_CPU) as p:
# results = p.map(get_review, candidate_list[:8])scraping 결과를 살펴보면

리뷰 개수는 평균 4개정도로 생각보다 너무 적었습니다.
16000개 다 사용하지 않고, 리뷰 개수가 특정 개수 이상인 것들만 사용할 생각입니다.

위와 같이 결과를 dict 형태로 바꿔, title_id를 통해 쉽게 review_df를 찾도록 바꿨습니다.
이제 이를 이용해 추천시스템을 구현해보겠습니다.
출처
그림1: https://www.imdb.com/title/tt13024974/reviews?sort=totalVotes&dir=desc&ratingFilter=0