[트리계열 이해하기] 6. LightGBM

LightGBM은 이름에서 알 수 있 듯 GBM 계열의 알고리즘을 더 가볍게 만든 모델입니다.
GBM 계열의 알고리즘들은 모든 데이터에 대해 스캔하여 IG를 획득하게 되는데,
" LGBM은 사용되는 Feature와 Data를 줄여 이 과정을 더욱 가볍게 만든 모델 " 입니다.
이를 위해 두 가지 기법을 사용합니다.
GOSS (데이터 줄이기) , EFB (피처 줄이기)
뿐만 아니라 트리를 발전시켜나가는 방향을 개선시켜 속도를 향상시켰습니다.
Leaf-wise (vs Level-wise , XGBoost )
1. GOSS
Gradient based One Side Sampling

GOSS의 컨셉은 "Gradient가 큰 데이터는 Keep하고 Gradient가 낮은 Data는 Randomly Drop을 수행한다는 것입니다."
즉, IG를 계산할 때 데이터마다 다른 Gradient를 갖고 있고, 크게 얻을게 없는 데이터는 랜덤하게 없앤다는 개념입니다.
Gradient가 크다는 것은 학습해야할 부분이 많다는 의미이고, 작다는 것은 학습할 부분이 별로 없다는 의미입니다.
따라서 기울기가 작은 것들에 대해서는 샘플링해서 사용하는 부분은 직관적입니다.
이를 통해 계산해야하는 데이터를 줄일 수 있습니다.
논문(1)에서는 $frac{(1-a)}{b} < 1$일 때 효과적이라고 이야기하고 있습니다.
2. EFB
Exclusive Feature Bundling
EFB의 컨셉은 독립적인 피처들(Exclusive Feature) 은 하나로 묶어서(Bundling) 처리해 계산해야하는 피처의 수를 줄이겠다는 것입니다.
이는 2가지 과정으로 진행됩니다.
- Step 1. Greedy Bundling : 어떤 Feature들을 하나로 Bundling 할 것인지 탐색
- Step 2. Merge Exclusive Features : 새로운 하나의 변수로 치환
2.1 Greedy Bundling
먼저 독립적이라는 것은 같은 값을 가지지 않는 횟수를 통해 파악할 수 있음을 직관적으로 이해할 수 있습니다.
왜 독립적인 것들로 묶지? 라는 의문이 생기는데,
독립적인 피처들로 묶어야 , 묶어도 데이터의 손실이 적기 때문입니다.
여기서는 Conflicts 강도를 계산해서 이를 기반으로 같이 묶을 피처를 파악합니다.
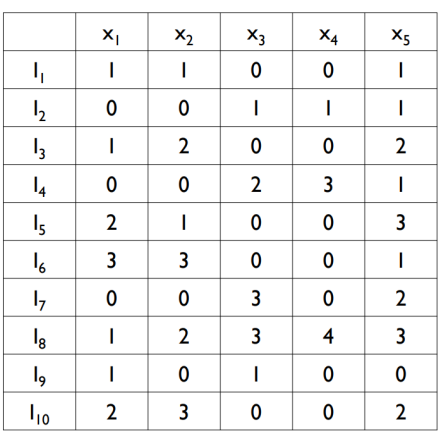
Conflicts 강도란 동시에 0이 아닌 횟수를 의미합니다.
즉, 두 피처 모두 값을 가지고 있는 횟수를 의미합니다.
One-Hot Encoding 시 두 개 모두 0이 아니라면 독립적이지 않을 것이라고 , 직관적으로 유추해볼 수 있습니다.
그림 2로부터 그림3과 같은 Confilcts 강도를 계산할 수 있습니다.
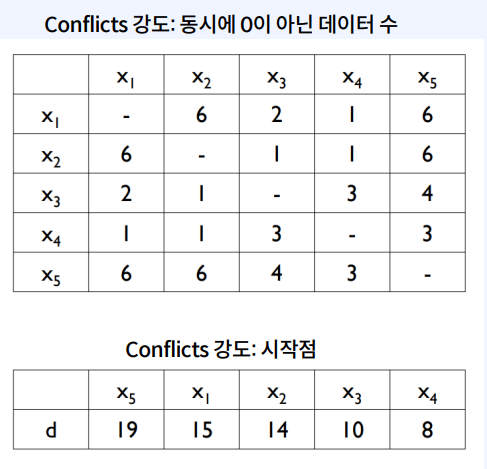
그리고 이를 바탕으로 독립적인 피처를 쉽게 찾기 위해 그래프를 그립니다.
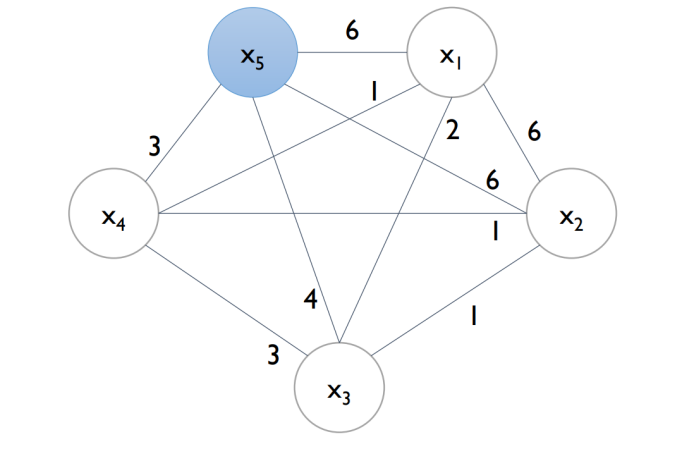
cut-off를 0.2로 설정했다면, 데이터의 개수가 10개이므로 2회 이상의 edge는 탈락시킵니다.
그 결과로 그림 5와 같은 그래프를 얻습니다.
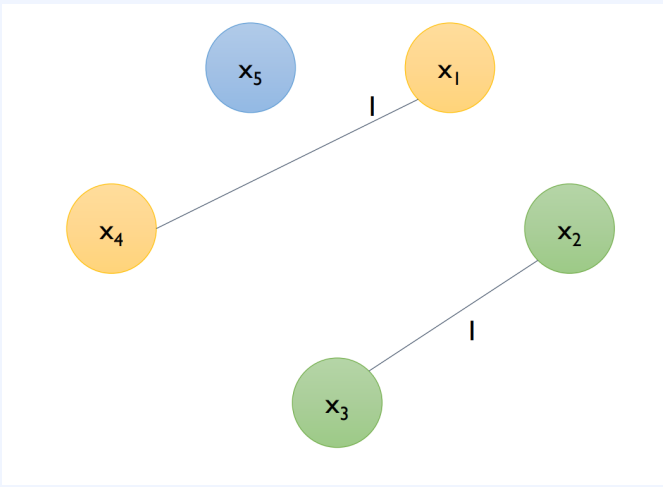
그림 5에 따라 x1-x4 , x3-x2 는 서로 독립적이며 이 것들을 하나의 bundle로 묶습니다.
2.2 Merge Exclusive Features
2.1로부터 찾은 피처들을 하나로 묶습니다.
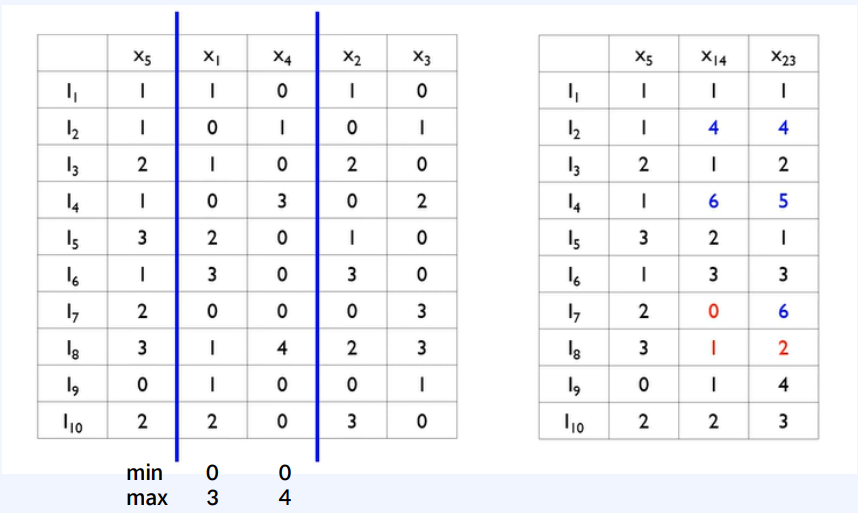
합치는 과정은 다음과 같은 규칙에 의해 이뤄집니다.
x1과 x4를 합치는 과정을 통해 이를 설명하겠습니다.
1. x1이 0이 아니면, 그대로 적는다.
2. x1이 0이고 x2가 0이 아니면, x4에 x1의 최댓값을 더해서 적는다.
3. 둘 다 0이면, 0으로 적는다.
이를 통해 데이터의 정보를 최대한 살리고 ( conflict를 최소화하고 ) 합칠 수 있었습니다.
이는 x1x4로부터 x1과 x4를 분리해낼 수 있음을 뜻합니다.
다만 I_8을 보면 x4의 정보가 그냥 삭제되었음을 알 수 있습니다.
이처럼 이 과정에서 데이터의 정보가 손실되는 단점이 있습니다.
3. Leaf-wise

- level-wise : 노드의 층을 유지하면서 분기
- leaf-wise : 층과 관계없이 최하위 노드를 분기해나가는 것
XGBoost가 level-wise로 트리를 분기하는 것과 다르게,
LightGBM은 leaf-wise로 트리를 분기하여 속도를 증진시켰습니다.
level을 맞추기 위해서는 추가적인 연산이 필요한데 , 이를 제거했기 때문입니다.
다만 층이 깊어짐에 따라 오버피팅할 위험이 증가했습니다.
4. 정리
정리하자면 LightGBM은 XGBoost를 좀 더 가볍게 만들었다고 생각할 수 있습니다.
Bucket split에서 one side split을 통해 데이터의 수를 줄였고, EFB를 통해 피처의 수를 줄였습니다.
그리고 leaf-wise를 통해 연산량을 추가적으로 줄였습니다.
뿐만 아니라 gpu를 제공하는 등 다양한 기능도 추가되었습니다.
빠른 속도로 여러 값들을 빠르게 테스트해볼 때 LGBM을 사용합니다.
오버피팅이 쉽게 가능해 데이터 수가 적을 때는 좋은 성능을 보이지 못하는 단점이 있습니다.
다만 양질의 데이터가 준비되었을 때는 XGBoost와 함께 정형데이터셋에서는 killer model로 사용되고 있습니다.
- 출처
그림1: https://www.google.com/url?sa=i&url=https%3A%2F%2Fwww.researchgate.net%2Ffigure%2FLevel-wise-tree-growth-VS-leaf-wise-tree-growth_fig3_362591649&psig=AOvVaw34Gz8spIi7vXy85rj0Ijp-&ust=1690695654531000&source=images&cd=vfe&opi=89978449&ved=0CBEQjRxqFwoTCNCNlKGas4ADFQAAAAAdAAAAABAJ
- Reference
패스트캠퍼스, 초격차 패키지 : 50개 프로젝트로 완벽하게 끝내는 머신러닝